
A Twitter most kiadott egy részletes útmutatót, amely elmagyarázza, hogy az ajánlási algoritmusok hogyan szereznek be és rendeznek tartalmat a hírfolyamhoz.
Elon Musk még március közepén megígérte, hogy kiadja a Twitter forráskódját az ajánlási algoritmushoz – és ezt meg még sok minden mást is teljesített.
Amellett, hogy megosztotta GitHubon az ajánló algoritmus kódját, a Twitteren egy rövid megjegyzést is közzétett arról, hogy a csapat miért tette közzé az adatokat, az algoritmus működéséről pedig további részleteket a platform Engineering blogján osztott meg.
A Twitter szerint az ajánlási algoritmusok úgy működnek, hogy fontos kérdésekre próbálnak választ adni, mint például:
- Mekkora a valószínűsége annak, hogy a jövőben kapcsolatba lép egy másik felhasználóval?
- Melyek a Twitter közösségei, és melyek a felkapott tweetek ?
A Twitter a tweetekből, a felhasználói adatokból és az engagement adatokból kinyert információkat használja fel a tweetek rangsorolására, és kiszűri azokat a tartalmakat, amelyeket kevésbé fogunk élvezni.
Hogyan is működik ez a valóságban?
Az idővonal felépítése
A Twitter a For You idővonal mögötti mechanizmust „Home Mixer”-nek nevezi. Ez a tweetek beszerzésének, rangsorolásának és szűrésének folyamata, amely előállítja a számunkra javasolt tartalmat.
A Twitter azzal kezdi, hogy tweeteket gyűjt az általunk követett emberektől (hálózaton belüli források) és azoktól, akiket nem követünk (hálózaton kívüli források).
A hálózaton belüli és kívüli tweetek működése
A hálózaton belüli tweeteket a “Real Graph” nevű modell rangsorolja, amely „megjósolja két felhasználó engagement valószínűségét”. Ha a Real Graph úgy gondolja, hogy viszonylag nagy valószínűséggel kapcsolatba kerülünk egy tweet szerzőjével (és fordítva), akkor több tweetje fog megjelenni az idővonalunkon.
A hálózaton kívüli tweetek forrása egy kicsit bonyolultabb, mivel a Twitter algoritmusának okosan kell találgatnia, hogy valakinek a tartalmát vonzónak fogjuk találni, akkor is, ha nem követjük őket.
A Twitter ezeket az előrejelzéseket egy közösségi gráfok segítségével teszi lehetővé, és olyan kérdéseket tesz fel, mint például:
- Milyen tweetekkel léptek kapcsolatba a személyek akiket követek a közelmúltban?
- Ki kedveli ugyanazokat (vagy hasonló) tweeteket, mint mi, és mit kedveltek még a közelmúltban?
SimClusters és a felhasználók által létrehozott közösségek
A Twitter egyik leghasznosabb beágyazási tere a SimClusters. A SimClusters egy egyéni mátrixfaktorizációs algoritmus segítségével fedezi fel a befolyásos felhasználók által létrehozott közösségeket és témakategóriákba csoportosítja őket.
145 ezer ilyen közösség létezik, amelyek háromhetente frissülnek.
A felhasználók és a tweetek a közösségek terében jelennek meg, és több közösséghez is tartozhatnak. A közösségek mérete az egyes baráti csoportok néhány ezer felhasználójától a hírek és a popkultúra több százmillió felhasználójáig terjed.
Íme néhány a legnagyobb közösségek közül:
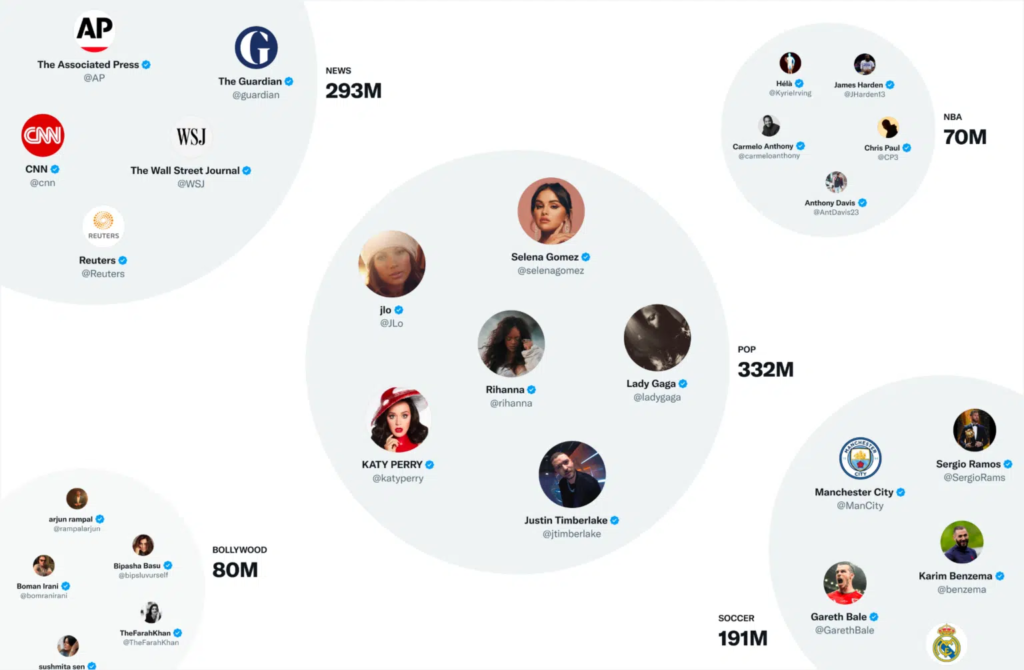
Ha egy tweet népszerű egy adott közösségen belül, akkor az adott közösségben több ember számára megjelenik.
Rangsorolás
Miután a Twitter körülbelül 1500 lehetséges tweetet gyűjtött az idővonalunkhoz mind a hálózaton belüli, mind a hálózaton kívüli forrásokból, rangsorolnia kell őket.
A Twitter egy kicsit rejtélyesebb volt azzal kapcsolatban, hogy konkrétan hogyan rangsorolja a tweeteket, mondván:
„A rangsorolás egy 48 milliós paraméterű neurális hálózattal érhető el, amelyet folyamatosan képeznek a Tweet-interakciókra, hogy optimalizálják a pozitív engagementet (pl. kedvelések, megosztások és válaszok). Ez a rangsorolási mechanizmus több ezer funkciót vesz figyelembe, és tíz címkét ad ki, hogy minden tweetnek egy pontszámot adjon, ahol minden címke az elköteleződés valószínűségét jelzi. Ezekből a pontszámokból rangsoroljuk a Tweeteket.”
– Twitter Team
Jelenleg úgy tűnik, hogy a csak URL-címet tartalmazó tweetek lejjebb kerülnek, míg a kedvelések és a retweetek jelentősen növelik a láthatóságot.
A rangsorolást követően a Twitter algoritmusai elkezdik kiszűrni a tartalmat olyan dolgok alapján, mint például, hogy kit blokkoltunk vagy némítottunk, kit láttunk mostanában sokat, és minden olyan hálózaton kívüli tartalom, amellyel az általunk követett személyek nem foglalkoztak.
Végszó
A Home Mixer átfutása után az ajánlott tartalom olyan dolgokkal keveredik, mint a hirdetések, és követési ajánlások a végső idővonal létrehozásához.
A Twitter szerint a teljes folyamat körülbelül 1,5 másodpercet vesz igénybe, és naponta 5 milliárd alkalommal fut le.
Források:
https://blog.hootsuite.com/social-media-updates/twitter/twitter-reveals-how-its-recommendation-algorithm-works/
https://blog.twitter.com/en_us/topics/company/2023/a-new-era-of-transparency-for-twitter
https://blog.twitter.com/engineering/en_us/topics/open-source/2023/twitter-recommendation-algorithm



Hozzászólások